Which Type of Data is Easy to Process by a Computer
What is raw information?
Raw data (sometimes called source data, atomic data or primary information) is data that has not been processed for use. A distinction is sometimes fabricated between data and information to the upshot that information is the end production of information processing. Raw data that has undergone processing is sometimes referred to as cooked data.
Although raw data has the potential to get "information," it requires selective extraction, arrangement and sometimes analysis and formatting for presentation. Considering of processing, raw information sometimes ends up in a database, which enables the data to go accessible for farther processing and analysis in a number of different means.
How raw data works
Tremendous amounts of raw data surround us and are produced every day. The man brain is incredibly good at taking in raw data, processing it and using it to brand decisions.
For example, imagine you are trying to cross a busy road. The eyes capture raw data every bit flashes of light and nighttime. So the brain takes these flashes and resolves them into objects such equally street signs and cars. The working memory tin can tell you lot if that car is sitting withal, getting bigger as it comes toward y'all, or getting smaller as it drives away. Meanwhile, the ears take in raw data in the form of vibrations in the air, which the brain translates into sounds that can be interpreted as the wind, voices or a car engine. Finally, all this candy data that came in through the eyes, ears and memory helps y'all brand the informed decision to cross the street or not.
Computers cannot intuitively process raw data like a homo mind can, nevertheless, and raw information is generally not useful on its own. Extra processing is required to turn it into useful information. Additionally, the final data from 1 organisation may exist used as raw information in some other.
For instance, imagine a uncomplicated home thermostat. Its raw data source is a temperature probe -- usually read equally an analog voltage level. The organisation takes this voltage level as raw data and turns it into a temperature reading. It tin then utilise this processed data to encounter a predetermined desired temperature for turning on and off a heater or air conditioner.
Furthermore, the system may feed this temperature reading and the current fourth dimension into some other climate control system as that system's raw data. Then the data is stored and analyzed over time to produce a predictive modeling algorithm to aid make meliorate heating and cooling decisions.
How to process raw information
Many sources can produce raw data. How it is processed and stored depend on its source and intended use, though. Examples of raw information can be financial transactions from a bespeak of sale (POS) last, computer logs or even participant eye tracking data in a research projection. Applications and devices can save raw information in various formats, but the most common format for interchanging raw data between systems is equally a comma separated values (CSV) file.
In many instances, users must make clean raw information before information technology tin can be used. Cleaning raw information may require parsing the data for easier ingestion into a computer, removing outliers or spurious results and, occasionally, reformatting or translating the data -- a procedure sometimes called massaging or crunching the information.
There are many means to procedure raw data, ranging from uncomplicated to complex. A spreadsheet such as Microsoft Excel or Google sheets allows users to format, organize and graph data to reveal elementary trends and assist summarize data. More complicated systems such as business organisation intelligence (BI) programs may employ raw information for financial trending or forecasting purposes. Advanced systems may apply raw data for alerting purposes or with machine learning to build models of the data and its behavior.
Value of raw data
The primary value in information is after it has been processed and interpreted. There is by and large not much value in holding onto raw information without a manner to apply information technology, but as the cost of storage decreases, organizations are finding more and more value in collecting raw data for boosted processing -- if not right away, and then later.
Raw data may contain personally identifiable data (PII). This may make an organization liable for storing or transmitting it. Therefore, it may utilize data anonymization to remove PII from the raw data or data controls and implement data memory policies to limit the gamble of data leaks.
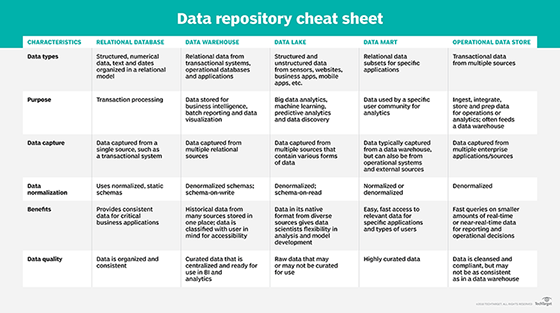
Organizations tin can feed raw information into a database or a data warehouse (one of several kinds of information repositories -- come across prototype above), which tin collect raw data from many sources for automated or transmission correlating and processing. An analysist can then query the data using BI tools to produce useful information from the data.
Many large businesses today recognize the value of raw data. Consumer data is a hot article that they can buy and sell to build profiles of users or target a specific audience, for example. Businesses tin can also store operational and logging data for use in performance metrics and to streamline business practices, while they can use access logs and the similar to identify estimator breaches and rail what data may have been accessed past hackers.
Also run across data lake, big data, big data analytics and information governance.
This was last updated in May 2021
Keep Reading About raw data (source data or atomic information)
- Top 7 predictive analytics use cases in enterprises
- Collaborative analytics benefits enterprise data analysis
- Combining AI and predictive analytics crucial for the enterprise
- Understanding and comparison six types of data processing systems
- Understanding object storage vs. block storage for the cloud
Dig Deeper on Data governance
-

Arm processor

By: Robert Sheldon
-

smart sensor

By: Brien Posey
-

data preprocessing

By: George Lawton
-

5-step predictive analytics process cycle
By: George Lawton
Source: https://www.techtarget.com/searchdatamanagement/definition/raw-data
{kind=link}
Post a Comment for "Which Type of Data is Easy to Process by a Computer"